
英超收官10大悬念 曼市刷史夺冠?萨拉赫争金靴?
曼市第5次捧起联赛杯奖杯。 (伦敦30日综合电)本周末,英超重燃战火,20队为了各自的目标在剩余的8轮联赛展...


We have very sort of, well, we have exercises for calibrating experts to help them think probabilistically. Then we ask them very targeted questions that can be where their responses can directly be used as data to influence our models,” Irvine said. CrowdStrike’s launch of Falcon for Insurability defines a new era in how AI and LLMs are revolutionizing cyber insurance. The new program is designed to give cyber insurers the flexibility they need to provide their clients and prospects with AI-native cyber protection using the CrowdStrike Falcon cybersecurity platform at preferred rates. Daniel Bernard, chief business officer at CrowdStrike, told VentureBeat during a recent interview that he predicts the reduction in premiums will be in the 10 to 30% range. At-Bay, Corvus Insurance, Cowbell Cyber, Upfort and Resilience Insurance are providing AI-based solutions to help streamline cyber insurance.
Pre-trained language models (PLM) represent a subsequent phase in the evolution of language models following NLM. Early attempts at PLMs included ELMo [5], which was built on a Bidirectional LSTM architecture. These models are typically trained via self-supervision on extensive datasets, cementing their status as the primary methodology in the field.
Slator Pro Guide: Translation AI.
Posted: Tue, 03 Oct 2023 07:00:00 GMT [source]
Organizations can spend months going through the application process to get cyber insurance, only to be rejected with no explanation. A common vision all vendors have is to remove the barriers in front of companies that have been rejected for insurance in the past. Identifying which tools, apps and platforms their customers need to reduce the probability of a breach is the goal. It’s become table stakes to have human-in-the-middle AI workflows and architectures in cybersecurity, and that’s permeating cyber insurance as well. CrowdStrikes’ Managed Detection and Response (MDR) service is an example of why human-in-the-middle is essential.
If you’re new to the machine learning scene or if your computing power is on the lighter side, Mixtral might be a bit of a stretch. T5 is great for companies that require a versatile tool for a variety of text-to-text processing tasks, such as summarization, translation, and classification. Surprisingly, those large LLMs even show certain emerging abilities, i.e., abilities to solve tasks and to do things that they were not explicitly trained to do. Suppose we were to include the Wikipedia article on Colombia’s political history as context for the LLM.
Additionally, in the realm of coding, GPT-4 has shown tendencies to errors or hallucinations, particularly with newer APIs (knowledge as of January 2022). Enterprises will often need custom models to tailor language processing capabilities to their specific use cases and domain knowledge. You can foun additiona information about ai customer service and artificial intelligence and NLP. Custom LLMs enable a business to generate and understand text more efficiently and accurately within a certain industry or organizational context. LLMs are used in a wide range of industries, from retail to healthcare, and for a wide range of tasks. They learn the language of protein sequences to generate new, viable compounds that can help scientists develop groundbreaking, life-saving vaccines.
In this perspective, solely relying on fine-tuning or mere scaling isn’t an all-in-one solution. It’s a sensible to construct a system around LLMs, leveraging their innate reasoning prowess to plan, decompose the complex task, reason, and action at each step. Given that LLMs inherently possess commendable reasoning and tool-utilizing skills, our role is primarily to guide them to perform these intrinsic abilities in appropriate circumstances. NeMo offers a choice of several customization techniques and is optimized for at-scale inference of models for language and image applications, with multi-GPU and multi-node configurations.
As generative AI technology evolves, practicing the latest ChatGPT prompting strategies is crucial to learn more about how this tool responds to human input and leverage its full capabilities for your projects. During instruction-tuning, sample queries like “write a report,” are paired with actual reports to show the LLM varied examples. ” From tens of thousands of dialogue pairs, the LLM learns how to apply knowledge baked into its parameters to new scenarios. Alignment happens during fine-tuning, when a foundation model is fed examples of the target task, whether that’s summarizing legal opinions, classifying spam, or answering customer queries.
NeMo makes generative AI model development easy, cost-effective, and fast for enterprises. It is available across all major clouds, including Google Cloud as part of their A3 instances powered by NVIDIA H100 Tensor Core GPUs to build, customize, and deploy LLMs at scale. To learn more, see Streamline Generative AI Development with NVIDIA NeMo on GPU-Accelerated Google Cloud.
You can try this end-to-end enterprise-ready software suite is with a free 90-day trial. To ensure an LLM’s behavior aligns with desired outcomes, it’s important to establish guidelines, monitor its performance, and customize as needed. This involves defining ethical boundaries, addressing biases in training data, and regularly evaluating the model’s outputs against predefined metrics, often in concert with a guardrails capability. For more information, see NVIDIA Enables Trustworthy, Safe, and Secure Large Language Model Conversational Systems.
Once AI maturity sets in, businesses can accelerate efforts in AI to build their competitive edge, delighting customer experience. Additionally, red teaming in various domains is necessary to critically assess and test the model, identifying vulnerabilities, biases, inaccuracies, and areas for safety improvement. During the backward propagation process, how do we compute the gradients of the linear layers within each major layer?
It achieves 105.7% of the ChatGPT score on the Vicuna GPT-4 evaluation. There seems to be no escaping large language models (LLMs) nowadays, and you certainly won’t find reprieve in this publication. But if you’re having trouble getting LLMs to give you the responses you’re looking for, you might want to consider changing how you prompt them. https://chat.openai.com/ The way that a prompt is structured has a significant impact on the quality of the response provided. Here are three research-based tips to help you improve your prompting strategies and get more out of LLMs. Using specialized instructions, written by the model itself, IBM researchers show that this buried knowledge can be resurfaced.
Generative AI is an umbrella term that refers to artificial intelligence models that have the capability to generate content. In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools.
However, fine-tuning without sufficient human oversight may lead to unintended consequences, such as offensive outputs. This makes fine-tuning critical in improving the downstream applicability of an LLM. Thus, let’s understand how LLMs are trained and how to fine-tune them. Zero-shot learning refers to the remarkable ability of LLMs to perform a task for which they have not been explicitly trained. But what makes LLMs especially powerful is that one model can be used for a whole variety of tasks, like chat, copywriting, translation, summarization, brainstorming, code generation, and more.
Self.mha is an instance of MultiHeadAttention, and self.ffn is a simple two-layer feed-forward network with a ReLU activation in between. However, acquiring a comprehensive and unbiased dataset can be challenging. However, this pre-trained model still needs to be tweaked to perform specific tasks effectively. The task-specific model learns to make predictions or perform the desired task using the extracted features from the language model. The training process exposes the model to a diverse range of linguistic patterns, contextual information, and semantic relationships present in the data.
It’s actually not difficult to create a lot of data for our “next word prediction” task. There’s an abundance of text on the internet, in books, in research papers, and more. We don’t even need to label the data, because the next word itself is the label, that’s why this is also called self-supervised learning. A Large Language Model (LLM) is akin to a highly skilled linguist, capable of understanding, interpreting, and generating human language.
This suggests that these LLMs are already adequate to address diverse challenges. However, being closed systems, LLMs are unable to fetch the most recent data or specific domain knowledge. This limitation can lead to potential errors or “hallucinations” (i.e., generating incorrect responses). While fine-tuning the pretrained LLMs is a potential remedy, it compromises their generality, as it requires fine-tuning the transformer neural network weights and data collections across every specific domain. Additionally, LLMs have intrinsic limitations in domains like arithmetic operations and staying current with the latest information.
Please exercise caution when using AI tools with personal, sensitive or confidential information. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use. Mixtral 8x7B represents the cutting-edge advancement in sparse mixture-of-experts models.
Unlike in the past, large-scale deep learning models have a wider range of applications and stronger performance compared to ordinary models. However, with great power comes great responsibility, and evaluating these models has become more complex, requiring consideration of potential problems and risks from all aspects. Since the popularity of ChatGPT, many related studies have been published, including the survey and summary of LLMs evaluation in reference [119; 120], which is helpful for developing large-scale deep learning models. This section will introduce some testing datasets, evaluation directions and methods, and potential threats that need to be considered based on previous evaluation work on large models.
Available in sizes of 7 billion, 13 billion, and 34 billion parameters, CodeGen was created to create a streamlined approach to software development. Complexity of useWith the need for understanding language nuances and deployment in different linguistic contexts, BLOOM has a moderate to high complexity. Llama 2 isn’t a good fit for higher-risk or more niche applications as it’s not intended for highly specialized tasks, and there are some concerns about the reliability of its output. To make it easier for you to choose an open-source LLM for your company or project, we’ve summarized eight of the most interesting open-source LLMs available.

Also, learning without updates requires the model to rely entirely on its existing knowledge. LLMs can understand user queries, provide accurate responses, and even engage in contextual dialogues. With their self-attention mechanism, Transformers could effectively capture dependencies between all positions in the input sequence, regardless of their distance.
There is no clear number for what constitutes a Large Language Model, but you may want to consider everything above 1 billion neurons as large. So, from here on we will assume a neural network as our Machine Learning model, and take into account that we have also learned how to process images and text. The second problem is the relationship between language and its sentiment, which is complex — very complex.
Rule-based programming can seamlessly integrate these modules for cohesive operation. In textual unimodal LLMs, text is the exclusive medium of perception, with other sensory inputs being disregarded. This text serves as the bridge between the users (representing the environment) and the LLM. Consequently, all actions manifest as text-based instructions, be it generating text responses or activating external resources and tools.
We build a decision flow for choosing LLMs or fine-tuned models~protectfootnotemark for user’s NLP applications. As mentioned, the ability to act as an assistant and respond appropriately is due to instruction fine-tuning and RLHF. But all (or most of) the knowledge to answer questions itself was already acquired during pre-training. As a result, that skill has probably been learned during pre-training already, although surely instruction fine-tuning helped improve that skill even further.
![]()
In turn, it provides a massive increase in the capabilities of the AI model. While there isn’t a universally accepted figure for how large the data set for training needs to be, an LLM typically has at least one billion or more parameters. Parameters are a machine learning term for the variables present in the model on which it was trained that can be used to infer new content.
They can assist in generating engaging and informative content by offering suggestions, improving grammar and style, and providing topic-specific knowledge. They can process and translate text from one language to another while capturing the nuances and context of the original text. Recently, they have found numerous applications across various industries, transforming the way we interact with technology and process information. On average, the 7B parameter model would cost roughly $25000 to train from scratch.
LLMs are also used to create reimagined search engines, tutoring chatbots, composition tools, marketing materials, and more. You’ve taken your first steps in building and deploying a LLM application with Python. Starting from understanding the prerequisites, installing necessary Chat GPT libraries, and writing the core application code, you have now created a functional AI personal assistant. By using Streamlit, you’ve made your app interactive and easy to use, and by deploying it to the Streamlit Community Cloud, you’ve made it accessible to users worldwide.
You could describe what you want in details or just give a brief instruction and some example demonstrations. We’ve now reached a point where you pretty much understand the main mechanisms of the state-of-the art LLMs (as of the second half of 2023, anyway). The reason is that Large Language Models like ChatGPT are actually trained in phases. What we need is an extremely powerful Machine Learning model, and lots of data. First, even a small, low-quality 224×224 image consists of more than 150,000 pixels (224x224x3).
Language modeling (LM) is a fundamental approach for achieving cognitive intelligence in the field of natural language processing (NLP), and its progress has been notable in recent years [1; 2; 3]. With the evolution of deep learning, the early statistical language models (SLM) have gradually transformed into neural language models (NLM) based on neural networks. This shift is characterized by the adoption of word embeddings, representing words as distributed vectors. Notably, these word embeddings have consistently excelled in practical NLP tasks, profoundly shaping the field’s progress.

It may even be doing an incredibly good job, but what it doesn’t do is respond well to the kind of inputs you would generally want to give an AI, such as a question or an instruction. The problem is that this model has not learned to be, and so is not behaving as, an assistant. Finally, we can start talking about Large Language Models, and this is where things get really interesting. If you have made it this far, you should have all the knowledge to also understand LLMs. Let’s move on to a slightly different problem now, but one for which we will simply try to apply our mental model from before. In our new problem we have as input an image, for example, this image of a cute cat in a bag (because examples with cats are always the best).
Another interesting ability of LLMs is also reminiscent of human intelligence. It is especially useful if the task is more complex and requires multiple steps of reasoning to solve. For more complex tasks, you may quickly realize that zero-shot prompting often requires very detailed instructions, and even then, performance is often far from perfect. At this stage, we say that the LLM is not aligned with human intentions. Alignment is an important topic for LLMs, and we’ll learn how we can fix this to a large extent, because as it turns out, those pre-trained LLMs are actually quite steerable. So even though initially they don’t respond well to instructions, they can be taught to do so.
It uses pattern matching and substitution techniques to understand and interact with humans. Later, in 1970, another NLP program was built by the MIT team to understand and interact with humans known as SHRDLU. With each of these methods, be sure to evaluate the suitability of the outputs, as well as what qualities the prompts have that lead to desired outputs. Assign ChatGPT a role—as in an identity, point-of-view, or profession—to help guide the tool’s responses. ChatGPT can generate outputs based on the area of expertise related to the role you assign it. In this guide, we’ll go over key ChatGPT prompting strategies, including foundational processes you need for any project and advanced strategies for optimizing the outputs.
In training LLMs, a noteworthy approach to alignment tuning is based on Reinforcement Learning with Human Feedback (RLHF) [93]. This method involves collecting human feedback data to train a reward model (RM) for reinforcement learning. The RM serves as the reward function during reinforcement learning training, and algorithms such as Proximal Policy Optimization (PPO) [111] are employed to fine-tune the LLM. In this context, LLM is considered as the policy, and the action space is considered as the vocabulary of the LLM. The T5 (short for the catchy Text-to-Text Transfer Transformer) is a transformer-based architecture that uses a text-to-text approach.
If citations are generated as part of the output, they must verify that the corresponding sources are non-fictitious, reliable, relevant, and suitable sources, and check for text–source integrity. While large language models (colloquially termed “AI chatbots” in some contexts) can be very useful, machine-generated text (much like human-generated text) can contain errors or flaws, or be outright useless. Gemma is a family of open-source language models from Google that were trained on the same resources as Gemini.
A foundation model is so large and impactful that it serves as the foundation for further optimizations and specific use cases. Incorporating an evaluator within the LLM-based agent framework is crucial for assessing the validity or efficiency of each sub-step. This aids in determining whether to proceed to the next step or revisit a previous one to formulate an alternative next step. For this evalution role, either LLMs can be utilized or a rule-based programming approach can be adopted. Evaluations can be quantitative, which may result in information loss, or qualitative, leveraging the semantic strengths of LLMs to retain multifaceted information.
They have emerged as powerful tools in the field of natural language processing (NLP) and have completely revolutionized the way machines comprehend and generate human language. As the dataset is crawled from multiple web pages and different sources, it is quite often that the dataset might contain various nuances. We must eliminate these nuances and prepare a high-quality dataset for the model training. Remember that ChatGPT can understand and respond to human language because of a technology called natural language processing. The prompt doesn’t need to be overly formal; it just needs to be clear and specific. IBM researchers found that LLMs trained on contrasting examples outperform models tuned on good examples only, on benchmarks for helpfulness and harmlessness.
Human annotators provide contextual information, disambiguate ambiguous examples, and impart their understanding of nuanced language use. While pre-training is compute-intensive, fine-tuning can be done comparatively inexpensively. Fine-tuning is more important for the practical usage of such models.
There are several models, with GPT-3.5 turbo being the most capable, according to OpenAI. They do natural language processing and influence the architecture of future models. Next, the LLM undertakes deep learning as it goes through the transformer neural network process. The transformer model architecture enables the LLM to understand and recognize the relationships and connections between words and concepts using a self-attention mechanism. That mechanism is able to assign a score, commonly referred to as a weight, to a given item — called a token — in order to determine the relationship.
Training LLMs require vast amounts of text data, and the quality of this data significantly impacts LLM performance. Pre-training on large-scale corpora provides LLMs with a fundamental understanding of language and some generative capability. The first step in LLM training is collecting substantial corpora of natural language text.
Another emerging trend is the domain-specific training and fine-tuning of LLMs for particular sectors, facilitating a more adept adaptation to and understanding of industry-specific terminologies and contexts. Lastly, in the exploration of potential new architectures for LLMs the current landscape predominantly relies on the transformer architecture. While the transformer architecture naturally boasts advantages such as parallel computing and adaptability to various input modalities, its design typically necessitates fixed-size inputs.
The ranked examples are then fed back to the original LLM using the PPO algorithm. Through Salmon, enterprises can imprint their own goals and values on their chatbots. Communication is at the root of Wikipedia’s decision-making process and it is presumed that editors contributing to the English-language Wikipedia possess the ability to communicate effectively. It matters for communication to have one’s own thoughts and find an authentic way of expressing them.
Large Language Models learn the patterns and relationships between the words in the language. For example, it understands the syntactic and semantic structure of the language like grammar, order of the words, and meaning of the words and phrases. Be it X or Linkedin, I encounter numerous posts about Large Language Models(LLMs) for beginners each day.
StableLM is a series of open source language models developed by Stability AI, the company behind image generator Stable Diffusion. There are 3 billion and 7 billion parameter models available and 15 billion, 30 billion, 65 billion and 175 billion parameter models in progress at time of writing. Mistral is a 7 billion parameter language model that outperforms Llama’s language model of a similar size on all evaluated benchmarks. Mistral also has a fine-tuned model that is specialized to follow instructions. Its smaller size enables self-hosting and competent performance for business purposes.
With the rise of LLMs, parameter-efficient tuning has garnered increasing attention, with LoRA being widely employed in the latest releases of LLMs. LoRA [112] and its related advancements [116; 117] are noteworthy and deserve attention. In order to support the backward propagation of the model, All intermediate results in the GPU memory need to be saved during the forward propagation of the model. To optimize this process, a checkpoint mechanism, which does not save all intermediate results in the GPU memory but only retains certain checkpoint points is utilized. The best approach is to take your time, look at the options listed, and evaluate them based on how they can best help you solve your problems. All of these open-source LLMs are hugely powerful and can be transformative if utilized effectively.
We urge the users in the community to refer to the licensing information for public models and data and use them in a responsible manner. We urge the developers to pay special attention to licensing, make them transparent and comprehensive, to prevent any unwanted and unforeseen usage. In fact, neural networks are loosely inspired by the brain, although the actual similarities are debatable. They consist of a sequence of layers of connected “neurons” that an input signal passes through in order to predict the outcome variable.
They offer a spectrum of tools and interfaces, streamlining the deployment and inference processes for researchers and engineers across diverse application scenarios. The choice of a framework typically hinges on project requirements, hardware support, and user preferences. The basic idea of weight sharing is to use the same set of parameters for multiple parts of a LLM. Instead of learning different parameters for each instance or component, the model shares a common set of parameters across various parts.
Retrieval augmented generation (RAG) is an architecture that provides an LLM with the ability to use current, curated, domain-specific data sources that are easy to add, delete, and update. With RAG, external data sources are processed into vectors (using an embedding model) and placed into a vector database for how llms guide… fast retrieval at inference time. For more information about how to build a production-grade RAG pipeline, see the /GenerativeAIExamples GitHub repo. Each time the model generates a probability distribution, it considers the last generated item, which means each prediction impacts every prediction that follows.
This is where the knowledge of Natural Language Processing techniques (NLP) comes to the rescue. Further, learning a language is challenging, as it involves identifying intonation, sarcasm, and different sentiments. There are situations where the same word can have different meanings in different contexts, emphasizing the importance of contextual learning. Parallel computing, model compression, memory scheduling, and specific optimizations for transformer structures, all integral to LLM inference, have been effectively implemented in mainstream inference frameworks. These frameworks furnish the foundational infrastructure and tools required for deploying and running LLM models.
LLMs are trained on large quantities of data and have some innate “knowledge” of various topics. Still, it’s common to pass the model private or more specific data as context when answering to glean useful information or insights. If you’ve heard the term “RAG”, or “retrieval-augmented generation” before, this is the core principle behind it. Large language models (LLMs) are incredibly powerful general reasoning tools that are useful in a wide range of situations.
Finally, we’ll explain how these models are trained and explore why good performance requires such phenomenally large quantities of data. Consequently, they also served as the foundation for large language models (which we will understand shortly). This took language modeling to the next level by incorporating massive amounts of training data. By leveraging powerful computational resources, they achieved unparalleled language understanding and generation capabilities.
In fact, this is a level or two more complicated than what we saw with images, which as we saw are essentially already numeric. We won’t go into details here, but what you need to know is that every word can be turned into a word embedding. Second, if you think about the relationship between the raw pixels and the class label, it’s incredibly complex, at least from an ML perspective that is. Our human brains have the amazing ability to generally distinguish among tigers, foxes, and cats quite easily.

On the internet betting has actually transformed the me...
Vending machine have come a lengthy method given th...
En ocasiones, nos encontramos en situaciones en las...
On the internet betting has actually transformed the me...
ContentAz?rbaycan üçün 1win Proqram?n? Yükl?m?y? BonusI...
ContentŞirkət Haqqında Rəsmi ElanRulet Oyunu💵 U...

曼市第5次捧起联赛杯奖杯。 (伦敦30日综合电)本周末,英超重燃战火,20队为了各自的目标在剩余的8轮联赛展...

新加盟車路士的基奧特於周四首次投入大軍操練,名宿蘇拿表示這位法國中鋒對車仔作用很大,且能減輕艾華路莫拉達的壓力...

多蒙特教練史杜加對借將巴舒亞伊讚不絕口,認為他要融入球隊絕無困難。 多蒙特日前由車路士借得24歲比利時前...
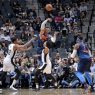
3月30日,NBA常规赛继续进行,圣安 东尼奥马刺坐镇主场迎战雷霆,两队激战到最后时刻,阿德在最后53秒关键的...

36岁的NBA大前锋萨克兰多夫,日前被搜出身上藏有2磅大麻而遭警方拘捕,但已经获释。 据《TMZ...

NBA新球季即將於月底展開季前訓練營,美媒「Fansided」專欄作家鄧克(Tyler Dencker...
 名字: 丹尼尔·沃森
名字: 丹尼尔·沃森