
英超收官10大悬念 曼市刷史夺冠?萨拉赫争金靴?
曼市第5次捧起联赛杯奖杯。 (伦敦30日综合电)本周末,英超重燃战火,20队为了各自的目标在剩余的8轮联赛展...


Thanks to data limitations, developers found a gap for voken alignment when used with Stable Diffusion. Despite this limitation, the MiniGPT-5 framework outperforms the current state of the art baseline GILL framework across all metrics. The idea to first leverage CFG for multimodal generation came as a result of an attempt to enhance consistency & logic between the generated images & texts, and the CFG is introduced during the text to image diffusion process.
GPT-4.5 or GPT-5? Unveiling the Mystery Behind the ‘gpt2-chatbot’: The New X Trend for AI.
Posted: Tue, 30 Apr 2024 07:00:00 GMT [source]
In the future, major internet companies and leading AI startups in both China and the United States will have the ability to build large models that can rival or even surpass GPT-4. And OpenAI’s most enduring moat lies in their real user feedback, top engineering talent in the industry, and the leading position brought by their first-mover advantage. However, what we don’t know is whether they utilized the new exaFLOP GPU platforms from Nvidia in training GPT-5. A relatively small cluster of the Blackwell chips in a data centre could train a trillion parameter model in days rather than weeks or months.
For a company with “open” in its name, OpenAI is almost as tight lipped as Apple when it comes to new products — dropping them on X out of nowhere when they feel the time is right. The timing of Orion’s release is pivotal for OpenAI, coinciding with the organization’s transition to a for-profit entity. Perhaps this is why the company focuses on revealing it to partners rather than the general public first. This shift comes from the recent funding round that raised $6.6 billion. The 1 trillion figure has been thrown around a lot, including by authoritative sources like reporting outlet Semafor. You can foun additiona information about ai customer service and artificial intelligence and NLP. While the 1.76 trillion figure is the most widely accepted estimate, it’s far from the only guess.
In March 2023, for example, Italy banned ChatGPT, citing how the tool collected personal data and did not verify user age during registration. The following month, Italy recognized that OpenAI had fixed the identified problems and allowed it to resume ChatGPT service in the country. In fact, OpenAI has left several hints that GPT-5 will be released in 2024. For background and context, OpenAI published a blog post in May 2024 confirming that it was in the process of developing a successor to GPT-4.

“I think there’s been way too much focus on parameter count, maybe parameter count will trend up for sure. But this reminds me a lot of the gigahertz race in chips in the 1990s and 2000s, where everybody was trying to point to a big number,” Altman said. While activation of the model for inference can be selective, training is all-encompassing, huge, and expensive.
Despite facing challenges in iPhone sales in China due to increasing competition, Apple is now poised to respond with its latest AI advancements. ChatGPT, the Natural Language Generation (NLG) tool from OpenAI that auto-generates text, took the tech world by storm late in 2022 (much like its Dall-E image-creation AI did earlier that year). Now, the company’s text-creation technology has leveled up to version 4, under the name GPT-4 (GPT stands for Generative Pre-trained Transformer, a name not even an Autobot would love). The table above compares the performance of three frameworks on 5,000 samples for multimodal generation from the aspects of Multimodal Coherence, Image Quality, and Language Continuity. As it can be observed, the MiniGPT-5 framework outperforms the other two baseline models by more than 70% cases. On the other hand, the table below demonstrates the performance of the MiniGPT-5 framework on the CC3M validation dataset for the generation of single images.
Otherwise, Llama 3 uses a mix of “public” internet data and synthetic AI-generated data. Increasing batch size is the most efficient approach because larger batches generally achieve better utilization. However, certain partitioning strategies that are inefficient for small batch sizes become efficient as the batch size increases. More chips and larger batch sizes are cheaper because they increase utilization, but they also introduce a third variable, network time. Some methods that partition the model across different chips are more efficient for latency but trade off with utilization.
Memory time and non-attention computation time are directly proportional to the model size and inversely proportional to the number of chips. However, for a given partition layout, the time required for chip-to-chip communication decreases slowly (or not at all), so it becomes increasingly important and a bottleneck as the number of chips increases. While we have only briefly discussed it today, it should be noted that as batch size and sequence length increase, ChatGPT App the memory requirements for the KV cache increase dramatically. If an application needs to generate text with long attention contexts, the inference time will increase significantly. Currently, using about 8,192 H100 chips at a price of $2 per hour, pre-training can be completed in about 55 days at a cost of about $21.5 million. It should be noted that we believe that by the end of this year, there will be 9 companies that will have more H100 chips.
However, OpenAI’s CTO has said that GPT-4o “brings GPT-4-level intelligence to everything.” If that’s true, then GPT-4o might also have 1.8 trillion parameters — an implication made by CNET. Each of the eight models within GPT-4 is composed of two “experts.” gpt 5 parameters In total, GPT-4 has 16 experts, each with 110 billion parameters. In turn, AI models with more parameters have demonstrated greater information processing ability. The number of tokens an AI can process is referred to as the context length or window.

If OpenAI really wants to achieve optimal performance, they need to train twice as many tokens. MoE (Mixture of Experts) is a good method to reduce the number of parameters during inference, but at the same time, it increases the number of parameters. This does not include all the experiments, failed training sessions, and other costs such as data collection, RLHF, and labor costs. Nvidia CEO Jensen Huang revealed during GDC that GPT-4 had 1.8 trillion parameters and required 30 yottaflops of compute power to train — that is like having a billion PS5s running constantly for 93,000 years. Speculation has surrounded the release and potential capabilities of GPT-5 since the day GPT-4 was released in March last year. Collins says that Gemini is “state of the art in nearly every domain” and that it is still in testing to determine exactly how capable it is at working in different mediums, languages and applications.
Instead of piling all the parameters together, GPT-4 uses the “Mixture of Experts” (MoE) architecture. Previous AI models were built using the “dense transformer” architecture. ChatGPT-3, Google PaLM, Meta LLAMA, and dozens of other early models used this formula. An AI with more parameters might be generally better at processing information. While this has not been confirmed by OpenAI, the 1.8 trillion parameter claim has been supported by multiple sources. Now that GPT-4o gives free users many of the same capabilities that were only available behind a Plus subscription, the reasons to sign up for a monthly fee have dwindled — but haven’t disappeared completely.

The best proof that OpenAI might be close to launching an even more capable ChatGPT variant is a rumor concerning internal discussions about new ChatGPT subscription plans. OpenAI is apparently considering prices that go up to $2,000 per month for access to its models, which is 100 times what ChatGPT Plus currently costs. Altman says they have a number of exciting models and products to release this year including Sora, possibly the AI voice product Voice Engine and some form of next-gen AI language model. One of the biggest changes we might see with GPT-5 over previous versions is a shift in focus from chatbot to agent. This would allow the AI model to assign tasks to sub-models or connect to different services and perform real-world actions on its own. Each new large language model from OpenAI is a significant improvement on the previous generation across reasoning, coding, knowledge and conversation.
The co-founder of LinkedIn has already written an entire book with ChatGPT-4 (he had early access). An account with OpenAI is not the only way to access GPT-4 technology. Quora’s Poe Subscriptions is another service with GPT-4 behind it; the company is also working with Claude, the “helpful, honest, and harmless” AI chatbot competition from Anthropic. OpenAI began a Plus pilot in early February (which went global on February 10); ChatPGT+ is now the primary way for people to get access to the underlying GPT-4 technology. PEFT or Parameter Efficient Fine Tuning is a crucial concept used to train LLMs, and yet, the applications of PEFT in multimodal settings is still unexplored to a fairly large extent.

It is worth noting that this release time differs significantly from earlier rumors. Chris Smith has been covering consumer electronics ever since the iPhone revolutionized the industry in 2008. When he’s not writing about the most recent tech news for BGR, he brings his entertainment expertise to Marvel’s Cinematic Universe and other blockbuster franchises. As Reuters reports, the company has 1 million paying users across its business products, ChatGPT Enterprise, Team, and Edu.
It was likely drawn from web crawlers like CommonCrawl, and may have also included information from social media sites like Reddit. There’s a chance OpenAI included information from textbooks and other proprietary sources. Meta’s open-source model was trained on two trillion tokens of data, 40% more than Llama 1. Parameters are what determine how an AI model can process these tokens. The connections and interactions between these neurons are fundamental for everything our brain — and therefore body — does. In June 2023, just a few months after GPT-4 was released, Hotz publicly explained that GPT-4 was comprised of roughly 1.8 trillion parameters.

That caused server capacity problems, so it didn’t take long for OpenAI, the company behind it, to offer a paid version of the tech. Which didn’t slow things down very much; ChatGPT (both paid and free versions) eventually attracted as much web traffic as the Bing search engine. There are still moments when basic ChatGPT exceeds capacity—I got one such notification while writing this story. A new and improved version of ChatGPT has landed, delivering great strides in artificial intelligence. An even older version, GPT-3.5, is available for free but has a smaller context window.
GPT-5 significantly delayed? OpenAI CTO said it will be launched at the end of 2025 or early 2026.
Posted: Sun, 23 Jun 2024 07:00:00 GMT [source]
One of the reasons OpenAI chose 16 experts is because more experts are difficult to generalize across many tasks. In such a large-scale training run, OpenAI chooses to be more conservative in the number of experts. The goal is to separate training computation from inference computation. That’s why it makes sense to train beyond the optimal range of Chinchilla, regardless of the model to be deployed. That’s why sparse model architectures are used; not every parameter needs to be activated during inference.
The company said the SambaNova Suite features larger memory that unlocks multimodal capabilities from LLMs, enabling users to more easily search, analyze, and generate data in these modalities. It also lowers total cost of ownership for AI models due to greater efficiency ChatGPT in running LLM inference, the company said. Although there was a lot of hype about the potential for GPT-5 when GPT-4 was first released, OpenAI has shot down all talk of GPT-5 and has made it clear that it isn’t actively training any future GPT-5 language model.
The Times of India, for example, estimated that ChatGPT-4o has over 200 billion parameters. This estimate first came from AI experts like George Hotz, who is also known for being the first person to crack the iPhone. In this article, we’ll explore the details of the parameters within GPT-4 and GPT-4o. Though we expect OpenAI will increase the limits for GPT-4o for both free and paid users, if you’d like to use GPT-4o for more than 15 messages every three hours, you’re better off with a ChatGPT Plus subscription. Read daily effectiveness insights and the latest marketing news, curated by WARC’s editors.

When it involves on the internet betting, benefit is vi...
Welcome to our thorough guide on gambling enterpris...
Online gambling enterprises have obtained enormous appe...
ContentAz?rbaycan üçün 1win Proqram?n? Yükl?m?y? BonusI...
ContentŞirkət Haqqında Rəsmi ElanRulet Oyunu💵 U...

曼市第5次捧起联赛杯奖杯。 (伦敦30日综合电)本周末,英超重燃战火,20队为了各自的目标在剩余的8轮联赛展...

新加盟車路士的基奧特於周四首次投入大軍操練,名宿蘇拿表示這位法國中鋒對車仔作用很大,且能減輕艾華路莫拉達的壓力...

多蒙特教練史杜加對借將巴舒亞伊讚不絕口,認為他要融入球隊絕無困難。 多蒙特日前由車路士借得24歲比利時前...
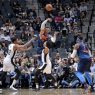
3月30日,NBA常规赛继续进行,圣安 东尼奥马刺坐镇主场迎战雷霆,两队激战到最后时刻,阿德在最后53秒关键的...

36岁的NBA大前锋萨克兰多夫,日前被搜出身上藏有2磅大麻而遭警方拘捕,但已经获释。 据《TMZ...

NBA新球季即將於月底展開季前訓練營,美媒「Fansided」專欄作家鄧克(Tyler Dencker...
 名字: 丹尼尔·沃森
名字: 丹尼尔·沃森